
Великі дані (англ. Big Data, BD) – це термін, що означає величезні обсяги даних структурованого та неструктурованого типу. Вони піддаються аналізу та ефективній обробці програмними інструментами. Big Data відкриває безліч можливостей для розвитку бізнесу: визначення цільової аудиторії та її потреб, побудова комунікації з клієнтами, націлення та багато іншого. Крім того, великі дані активно використовуються в інших сферах нашого життя. Незалежно від їх сфери застосування технології BD покликані виконувати такі операції:
- обробка великого обсягу даних;
- робота з даними, що постійно надходять;
- взаємодія зі структурованою та неструктурованою інформацією.
Вважається, що ці операції дозволяють визначати приховані закономірності, які часто вислизають від людського сприйняття. Це відкриває нові можливості для оптимізації процесів у багатьох сферах життя людини.
Особливості та принципи роботи Big Data
Крім великого обсягу даних BD має інші визначальні характеристики. Вони ще більше підкреслюють складність обробки та аналізу даних. Йдеться про VVV:
- Volume – фізичний обсяг.
- Velocity – швидкість приросту, яка потребує швидкої обробки.
- Variety – різноманітність форматів даних.
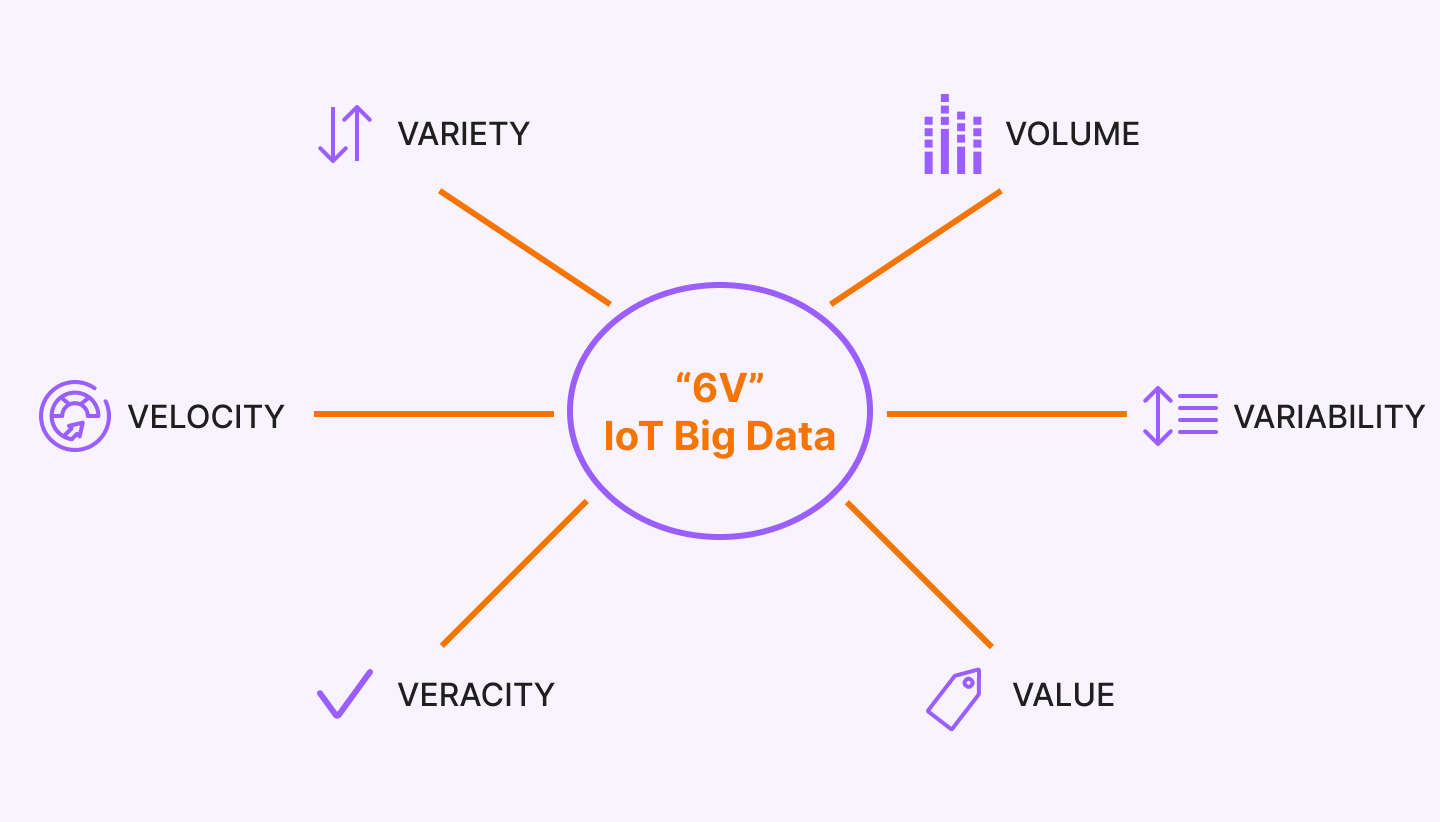
Поняття трьох V з'явилося ще у 2001 році та було розроблено компанією Meta Group. Автори хотіли підкреслити рівну значущість управління даними щодо кожного з трьох аспектів. Згодом до вже існуючих додали ще 3:
- Veracity – достовірність як набору даних, так і результатів його аналізу.
- Value – цінність та значимість даних.
- Variability – мінливість даних.
З аспектів можна вивести основні принципи великих даних:
- Горизонтальна масштабованість. Це основа основ обробки даних у зв'язку з постійним збільшенням їхнього обсягу. Це спричиняє впровадження в систему більшої кількості обчислювальних вузлів, при цьому якість обробки не повинна страждати.
- Відмовостійкість. Збільшення кількості обчислювальних вузлів може призводити до виходу з експлуатації машин. З чого можна зробити висновок, що методи роботи з Big Data повинні враховувати виникнення таких ситуацій та передбачати необхідні заходи щодо їх недопущення.
- Локальність даних. Зберігання та обробка даних має здійснюватися на одній машині. В іншому випадку, коли обчислювальні вузли знаходяться на одному сервері, а обробка здійснюється на іншому, це може призвести до суттєвих витрат.
Технології роботи з великими даними
Спочатку підходи та технології великих даних складалися із засобів масово-паралельної обробки невизначено структурованих даних, наприклад, NoSQL. Але з часом з'явилися інші інструменти та рішення, які підходили під характеристики, необхідні для обробки надвеликих масивів даних. Розглянемо їх докладніше:
- NoSQL – це загальний термін для нереляційних сховищ. Реляційний тип БД добре підходить для однотипних запитів, але при складних навантаженнях перевищує межі, і використання NoSQL стає просто неефективним.
- MapReduce – розробка Google, що ґрунтується на розподілених обчисленнях у комп'ютерних кластерах. Обробка даних проводиться паралельно у розподілених кластерах звичайними недорогими комп'ютерами.
- Hadoop – це набір інструментів, бібліотек та фреймворків. Він ділить файли великі блоки і потім розподіляє їх між вузлами кластера. Після цього дані потрапляють на паралельну обробку.
- R – мова програмування, створена для статичної обробки даних та роботи із графікою. Він отримав широке застосування в аналізі даних та визнаний стандартом статичних програм.
- Апаратні рішення – це комплекси у вигляді готових до встановлення телекомунікаційних шаф із кластером серверів та програмним забезпеченням для масово-паралельної обробки великих даних. Хорошим прикладом є: Hana, Exalytics.
- Data Mining – сукупність методів визначення корисних раніше невідомих знань, які необхідні прийняття рішень. Сюди можна зарахувати навчання асоціативним правилам, кластерний аналіз, визначення відхилень та інші.
- Машинне навчання (з або без вчителя) – використання моделей, які створені на основі статичного аналізу чи машинного навчання з метою отримання комплексних прогнозів.
- Штучні нейронні мережі (мережевий аналіз, генетичні алгоритми) - обчислювальні системи, здатні навчатися та аналізувати великі дані.
Методи аналізу великих даних
Існує кілька популярних методів аналізу великих даних:
- Описова аналітика (англ. descriptive analytics) – один із найпопулярніших методів. Він аналізує дані у реальному часі, а також працює з історичними даними. Його мета – визначити причини та закономірності успіхів чи невдач. Потім метод дозволяє використовувати отримані дані підвищення ефективності моделей. Приклад – вебстатистика Google Analytics або соціологічне дослідження.
- Предикативна аналітика – метод аналізу ВD, що допомагає спрогнозувати можливий розвиток подій на основі наявних даних. Для цього застосовуються сформовані шаблони з аналогічним набором характеристик. Наприклад, ця аналітика допомагає прогнозувати зміни цін на фондовому ринку.
- Приписна аналітика – це наступний рівень прогнозування. Вона дозволяє визначити проблемні точки, наприклад, у бізнесі, а потім прорахувати сценарій, за якого не допустити їх у майбутньому.
- Діагностична аналітика – метод, що дозволяє визначити причини того, що сталося. Він допомагає знайти аномалії та випадкові зв'язки між подіями та діями.
Звичайно ж, методів та інструментів аналізу більших даних більше. З кожним роком їхня кількість зростає, як і роль Big Data у житті людини. Ймовірно, у найближчому майбутньому БД стануть чи не основним інструментом прийняття рішень не лише у сфері електронної комерції, а й у глобальних проблемах людства.