
Big data is a term for a huge amounts of data of a structured and unstructured type. They can be analyzed and efficiently processed by software tools. Big data opens up many opportunities for business development: identifying the target audience and its needs, building communication with customers, targeting, and much more. In addition, Big data is actively used in other areas of our lives. Regardless of their scope, BD technologies are designed to perform the following operations:
- handling large amounts of data;
- working with constantly incoming data;
- interacting with structured and unstructured information.
It is believed that these operations allow you to identify hidden patterns that often elude human perception. This opens new opportunities for optimizing processes in many areas of human life.
Features and principles of Big data
In addition to the large amounts of data, a BD has other defining characteristics. They further emphasize the complexity of data processing and analysis. We are talking about VVV:
- Volume – physical volume.
- Velocity – the speed of growth and the need for rapid processing.
- Variety – a variety of data formats.
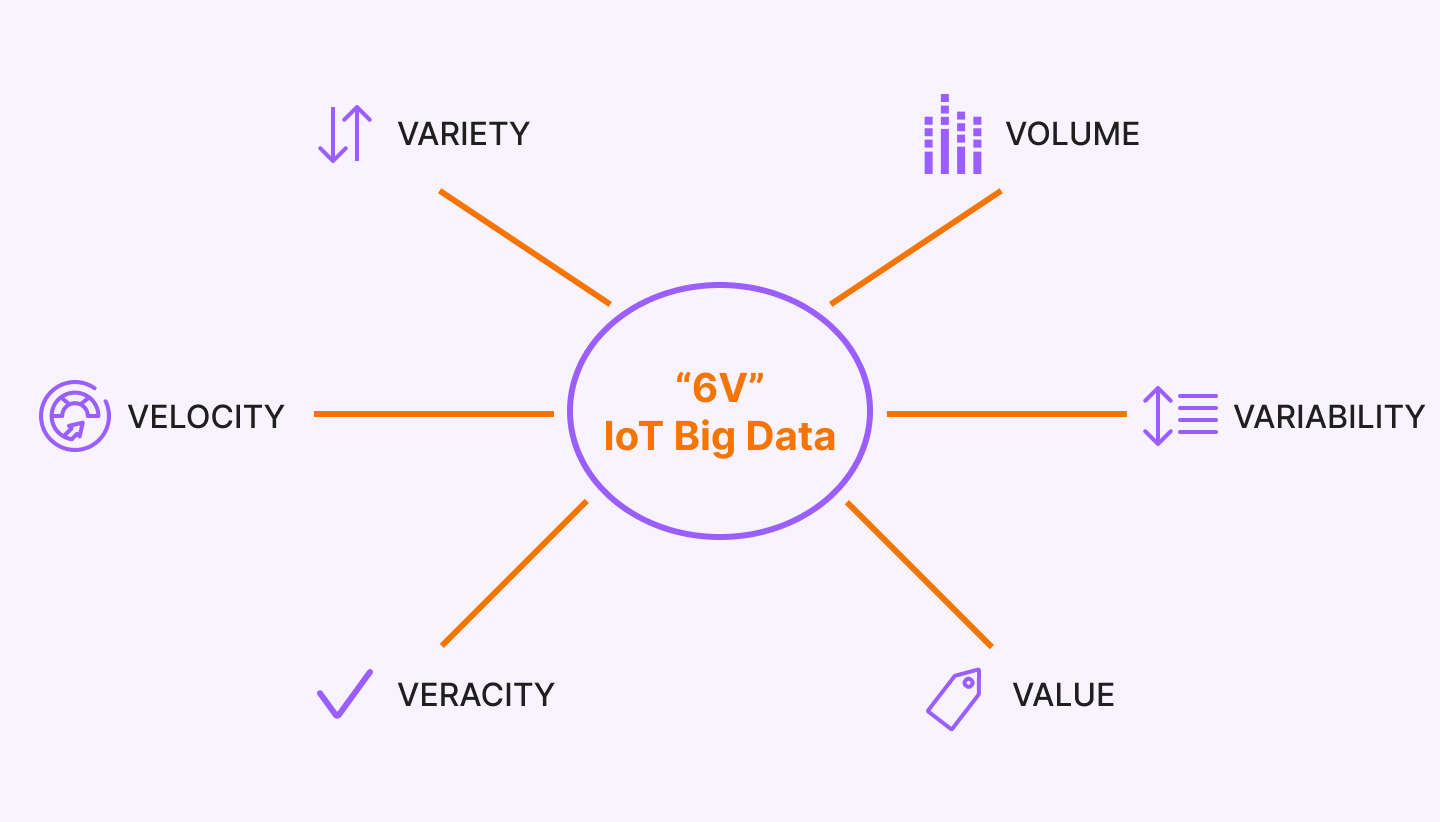
The concept of three V appeared in 2001 and was developed by Meta Group. The authors wanted to emphasize the equal importance of data management in each of the three aspects. With time, 3 more were added to the existing ones:
- Veracity - the reliability of both the data set and the results of its analysis.
- Value - the value and significance of the data.
- Variability – variability of data.
The main principles of Big data can be deduced from the aspects:
- Horizontal scalability. This is the basis of the fundamentals of data processing due to the constant increase in their volume. This entails the introduction of a larger number of computing nodes into the system, while the quality of processing should not suffer.
- Fault tolerance. An increase in the number of computing nodes can lead to the failure of machines. From which we can conclude that the methods of working with Big data should take into account the occurrence of such situations and provide for the necessary measures to prevent them.
- Data locality. Storage and processing of data should be carried out on the same machine. Otherwise, when computing nodes are located on one server, and processing is carried out on another, this can lead to significant costs.
Big data technologies
Initially, Big data approaches and technologies consisted of mass-parallel processing of indefinitely structured data, for example, NoSQL. But over time, other tools and solutions appeared that fit the characteristics necessary for processing super-large data sets. Let's take a look at them:
- NoSQL is a generic term for non-relational storage. The relational database type is well suited for homogeneous queries, but with complex loads it exceeds the limits, and the use of NoSQL becomes simply inefficient.
- MapReduce is a Google development, based on distributed computing in computer clusters. Data processing is carried out simultaneously in distributed clusters by ordinary inexpensive computers.
- Hadoop is a toolkit, libraries and frameworks. It divides the files into large blocks and then distributes them among the cluster nodes. After that, the data is sent for parallel processing.
- R is a programming language designed for static data processing and graphics. It has been widely used in data analysis and is recognized as a standard for static programs.
- Hardware solutions are complexes in the form of ready-to-install telecommunication cabinets with a server cluster and software for massively parallel processing of Big data. Good examples are: Hana, Exalytics.
- Data Mining is a set of methods for determining useful previously unknown knowledge that is necessary for decision making. This can include training in associative rules, cluster analysis, determination of deviations, and others.
- Machine learning (supervised or unsupervised) is the use of models that are based on static analysis or machine learning in order to obtain complex predictions.
- Artificial neural networks (network analysis, genetic algorithms) are computing systems capable of learning and analyzing Big data.
Big data Analysis Methods
There are several popular Big data analysis methods:
- Descriptive analytics is one of the most popular methods. It analyzes data in real time and also works with historical data. Its purpose is to determine the causes and patterns of success or failure. Then the method allows you to use obtained data to improve the performance of the models. An example is Google Analytics web statistics or a sociological study.
- Predictive analytics is a DB analysis method that helps to predict possible development of events based on the available data. For this, already formed templates with a similar set of characteristics are used. For example, this analytics helps predict price changes in the stock market.
- Prescriptive analytics is the next level of forecasting. It allows you to identify problem points, for example, in business, and then calculate the scenario in which to prevent them in the future.
- Diagnostic analytics is a method that allows you to determine the causes of what happened. It helps to find anomalies and random connections between events and actions.
Of course, there are more methods and tools for Big data analysis. Every year their number is growing, as is the role of Big data in human life. Probably, in the near future, databases will become almost the main decision-making tool not only in the field of e-commerce, but also in the global problems of mankind.